Liangming Pan
Sun 01 August 2021Introduction
Fact verification aims to validate a claim in the context of evidence. Given a claim and a piece of evidence as inputs, a fact verification model predicts a label to verify whether is supported, refuted, or can not be verified by the information in . Fact verification task has attracted growing interest with the rise in disinformation in news and social media. Rapid progress has been made by training large neural models on the FEVER dataset, containing more than 100K human-crafted (evidence, claim) pairs based on Wikipedia.
Fact verification is demanded in many domains, including news articles, social media, and scientific documents. However, it is not realistic to assume that large-scale training data is available for every new domain that requires fact verification. Creating training data by asking humans to write claims and search for evidence to support/refute them can be extremely costly.
Zero/Few-shot Fact Verification
Could we train a good fact checking model without human annotation? We explore this possibility of automatically generating large-scale (evidence, claim, label) data to train the fact verification model.
As illustrated in Figure 1 below, we propose a simple yet general framework Question Answering for Claim Generation (QACG) to generate three types of claims from any given evidence:
- Claims that are supported by the evidence
- Claims that are refuted by the evidence
- Claims that the evidence does Not have Enough Information (NEI) to verify
Zero-shot Fact Verification: We assume no human-annotated training example is available. We only use the generated (evidence, claim, label) data are used to train the fact verification model.
Few-shot Fact Verification: We assume only a few human-labeled (evidence, claim) pairs are available. We first train the fact verification model with the generated data. Then we fine-tune the model with the limited amount of human-labeled data.
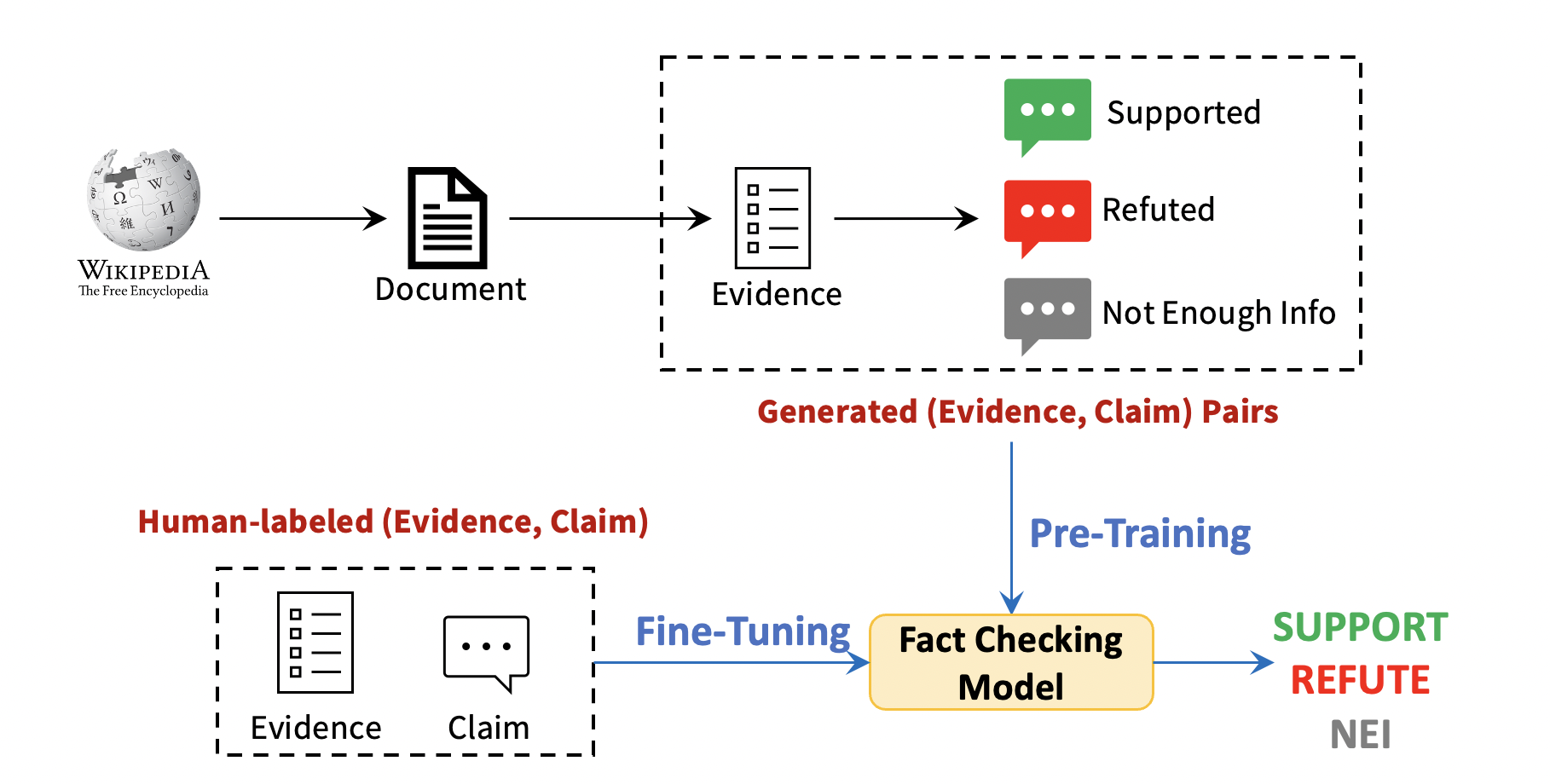
Figure 1—Our zero-shot fact verification framework.
Main Observations
Reducing Human Labor: pretraining the fact verification model with generated claims greatly reduces the demand for in-domain human annotation. - Zero-shot Setting: Although we do not use any human-labeled training examples, the model achieves over 70% of the F1 performance of a fully-supervised setting. - Few-shot Setting: By fine-tuning the model with only 100 labeled examples, we further close the performance gap, achieving 89.1% of fully-supervised performance.
Improving Robustness: When evaluating the model on an unbiased test set for FEVER, we find that training with generated claims also produces a more robust fact verification model.
Claim Generation Model
As illustrated in Figure 2 below, our claim generation model QACG has two major components:
Question Generator
A Question Generator takes as input an evidence and a text span from the given evidence and aims to generate a question with as the answer. We implement this with the BART model, a large transformer-based sequence-to-sequence model pretrained on 160GB of text. The model is finetuned on the SQuAD dataset processed by Zhou et al. (2017), where the model encodes the concatenation of the SQuAD passage and the answer text and then learns to decode the question.
QA-to-Claim model
The QA-to-Claim model takes as inputs and , and outputs the declarative sentence for the pair. We also treat this as a sequence-to-sequence problem and finetune the BART model on the QA2D dataset, which contains the human-annotated declarative sentence for each pair in SQuAD.
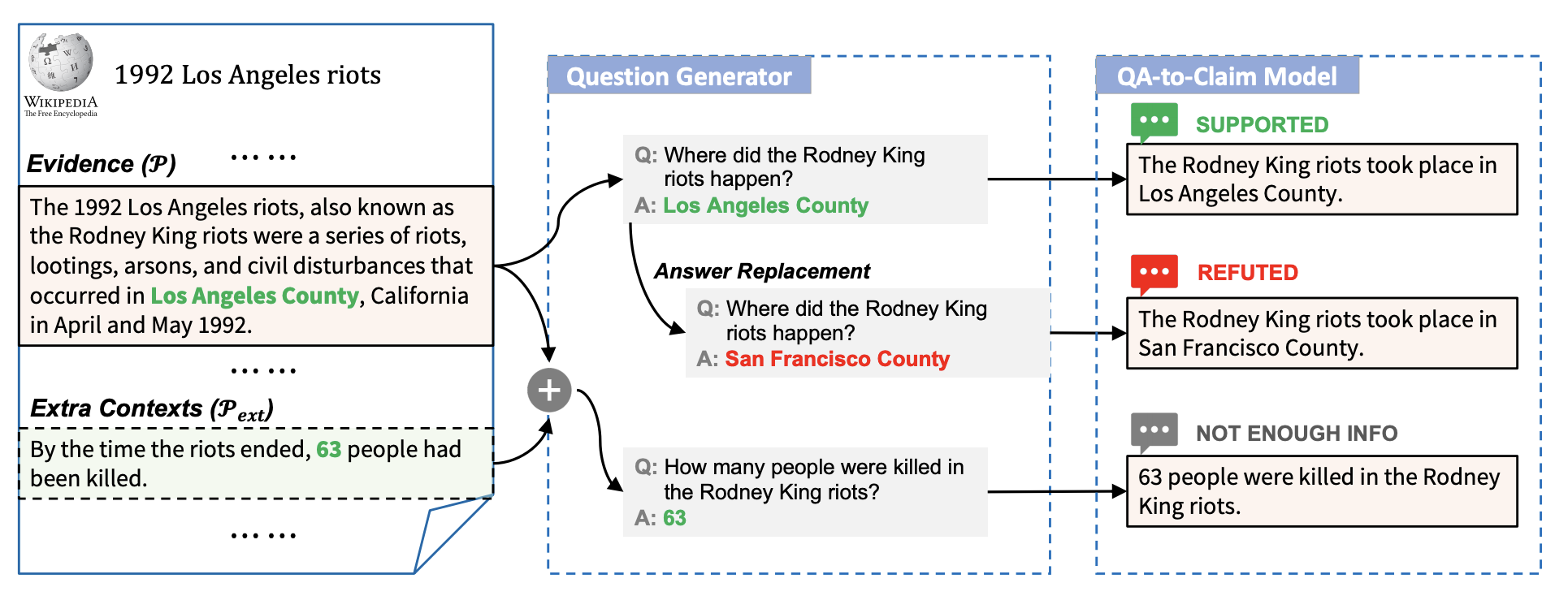
Figure 2—Our claim generation model.
Using the Model to Generate Claims
Given the pretrained question generator and the QA-to-Claim model , we then formally introduce how we generate claims with different labels.
Supported Claim Generation
Given an evidence , we use named entity recognition to identify all entities within . We treat each identified entity as an answer and generate a question with the question generator. The question–answer pair are then sent to the QA-to-Claim model to generate the supported claim .
Refuted Claim Generation
To generate a refuted claim, after we generate the question–answer pair , we use answer replacement to replace the answer with another entity with the same type such that becomes an incorrect answer to the question . Using as the query, we randomly sample a phrase from the top-5 most similar phrases in the pretrained Sense2Vec as the replacing answer . The new pair is then fed to the QA-to-Claim model to generate the refuted claim.
NEI Claim Generation
We need to generate a question which is relevant but cannot be answered by . To this end, we link back to its original Wikipedia article and expand the evidence with additional contexts , which are five randomly-retrieved sentences from that are not present in . As shown in the example in the above Figure, one additional context retrieved is "By the time the riots ended, 63 people had been killed". We then concatenate and as the expanded evidence, based on which we generate a supported claim given an entity in as the answer (e.g., "63"). This results in a claim relevant to but unverifiable by the original evidence .
Experiments
By applying our QACG model to each of the 18,541 Wikipedia articles in the FEVER training set, we generate a total number of 176,370 supported claims, 360,924 refuted claims, and 258,452 NEI claims.
Evaluation Datasets
- FEVER-S/R: Since only the supported and refuted claims are labeled with gold evidence in FEVER, we take the claim–evidence pairs of these two classes from the FEVER test set for evaluation.
- FEVER-Symmetric: this is a carefully-designed unbiased test set designed by Schuster et al. (2019) to detect the robustness of the fact verification model. Only supported and refuted claims are present in this test set.
- FEVER-S/R/N: The full FEVER test set are used for a three-class verification. We use the system of Malon (2019) to retrieve evidence sentences for NEI claims.
Zero-shot Fact Verification
Models for comparison:
- Supervised: the RoBERTa-large model fine-tuned on the FEVER training set as the supervised model.
- QACG: the RoBERTa-large model fine-tuned on our generated training set.
- Perplexity: It predicts the class label based on the perplexity of the claim under a pretrained GPT2 language model, following the assumption that "misinformation has high perplexity".
- LM as Fact Checker (Lee et al., 2020b): It leverages the implicit knowledge stored in the pretrained BERT language model to verify a claim.
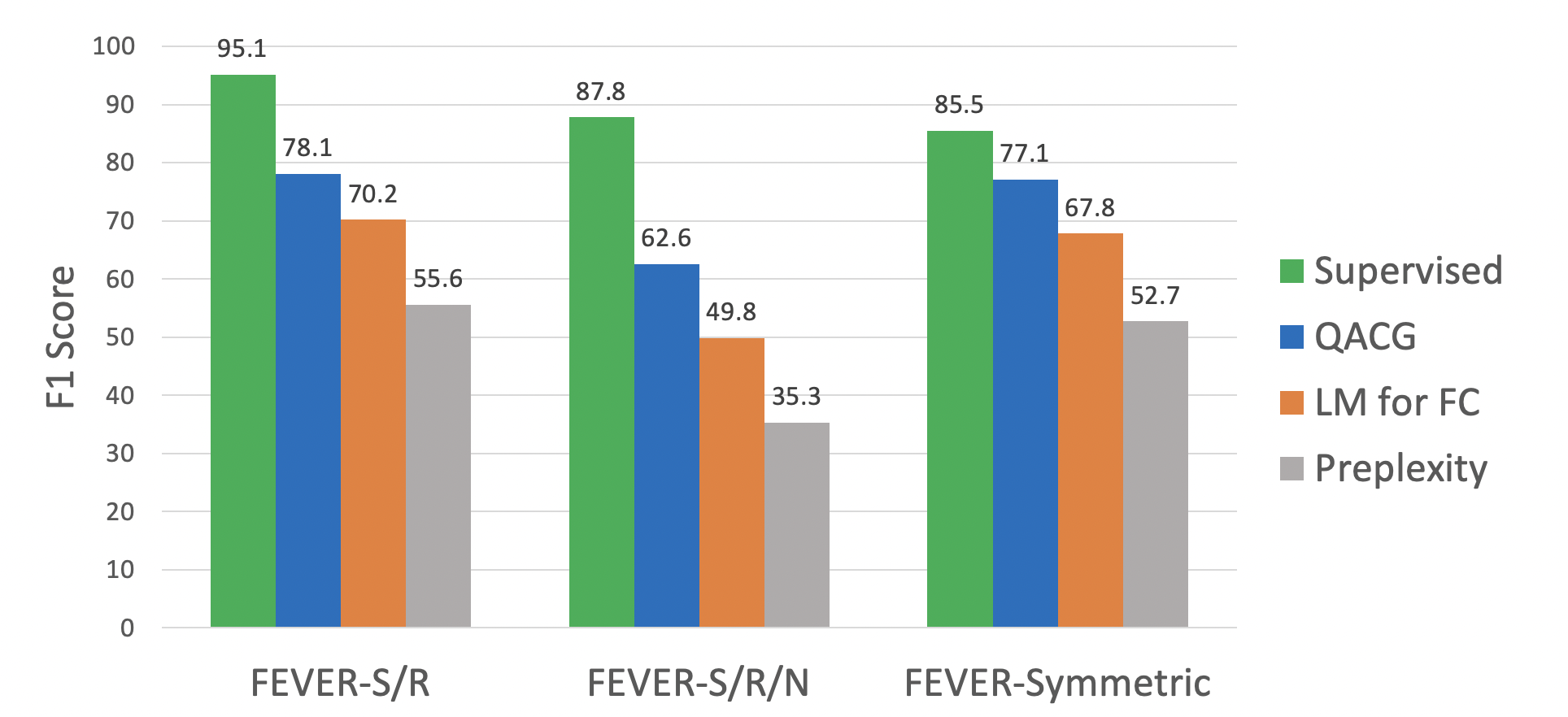
Figure 3—Our zero-shot experiment.
QACG attains 78.1 F1 on the FEVER-S/R and 62.6 F1 on the FEVER-S/R/N. Although QACG does not see any human-labelled (evidence, claim) pair in training, the F1 gap to the fully-supervised model is only 17.0 and 15.2 on these two settings, respectively. The results demonstrate the effectiveness of QACG in generating good (evidence, claim) pairs for training the fact verification model. We observe a large performance drop when the supervised model is evaluated on the FEVER-Symmetric test set (−9.6 F1). However, the models trained with our generated data drop only 1.2 and 1.0 F1 drop. This suggests that the wide range of different claims we generate as training data helps eliminate some of the annotation artifacts present in FEVER, leading to a more robust fact verification model.
Few-shot Fact Verification
The blue solid line in the below Figure shows the F1 scores on FEVER-Symmetric after fine-tuning with different numbers of labeled training data. We compare this with training the model from scratch with the human-labeled data (grey dashed line). Our model performs consistently better than the model without pretraining, regardless of the amount of labeled training data. The improvement is especially prominent in data-poor regimes. The results show pretraining fact verification with QACG greatly reduces the demand for in-domain humanannotated data. Our method can provide a "warm start" for fact verification system when applied to a new domain where training data are limited.
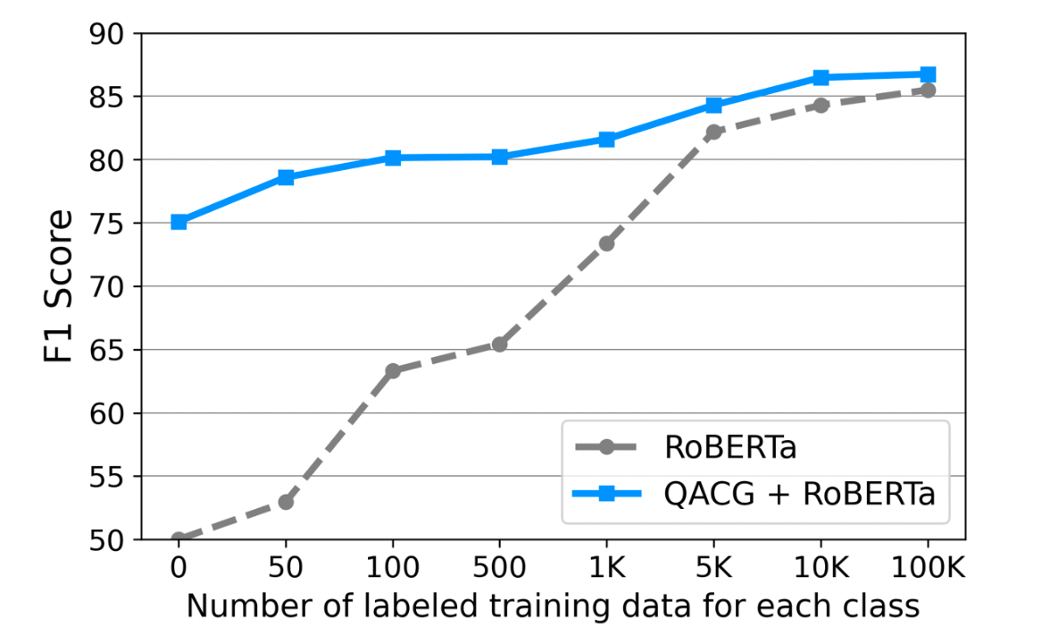
Figure 4—Our few-shot fact verification experiment.
Case Study
The below Table shows representative claims generated by our model. The claims are fluent, label-cohesive, and exhibit encouraging language variety. However, one limitation is that our generated claims are mostly lack of deep reasoning over the evidence. This is because we finetune the question generator on the SQuAD dataset, in which more than 80% of its questions are shallow factoid questions.
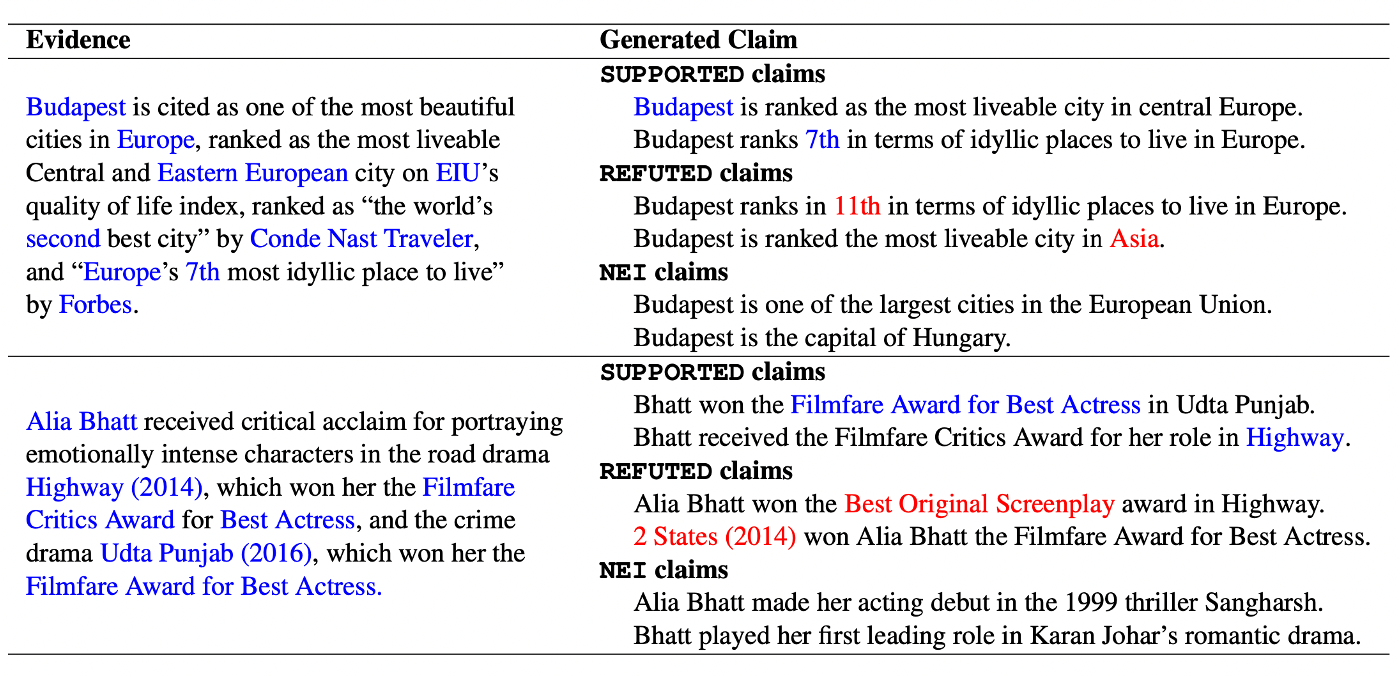
Figure 5—Example claims generated by our model in the case study.
Conclusion
In this work, we utilize the question generation model to ask different questions for given evidence and convert question–answer pairs into claims with different labels. We show that the generated claims can train a well-performing fact verification model in both the zero-shot and the few-shot learning setting. In summary, our contributions are:
- We explore the possibility of automatically generating large-scale (evidence, claim) pairs to train the fact verification model.
- We propose a simple yet general framework Question Answering for Claim Generation (QACG) to generate three types of claims from any given evidence: 1) claims that are supported by the evidence, 2) claims that are refuted by the evidence, and 3) claims that the evidence does Not have Enough Information (NEI) to verify.
- We show that the generated training data can greatly benefit the fact verification system in both zero-shot and few-shot learning settings.
You can check out our full paper here and our source code/data on GitHub. If you have questions, please feel free to email us.
- Liangming Pan: liangmingpan@u.nus.edu
- Wenhu Chen: wenhuchen@cs.ucsb.edu
Acknowledgments
This blog post is based on the paper:
- Zero-shot Fact Verification by Claim Generation. Liangming Pan, Wenhu Chen, Wenhan Xiong, Min-Yen Kan, and William Yang Wang. ACL-IJCNLP 2021.
Many thanks to my collaborators and advisors, Wenhu Chen, Wenhan Xiong, Min-Yen Kan and William Yang Wang for their help. Many thanks to Michael Saxon for edits on this blog post.