Written by Sharon Levy
Mon 02 August 2021Overview
What do language models memorize? As the creation and adoption of natural language generation (NLG) models increases, questions arise regarding the information these models learn. While it is known that NLG models produce biased and harmful text, most studies do not evaluate what leads to these generations: memorization of training data.
In our ACL 2021 Findings paper, we aim to determine the extent to which GPT-2 (and other language models) memorizes and generates harmful information. Unlike previous studies, we perform our analysis without access to the model's training data. While this makes the task of detecting memorized data more difficult, it allows our methods to generalize to models that do not release their large-scale training sets alongside published models. Additionally, we perform our analysis with regards to a particularly dangerous type of misinformation: conspiracy theories.
We propose methods to evaluate the memorization of this text, through various model settings and linguistic analysis.
Memorization in NLG Models
In general, generated text can be broken down into three categories:
- Memorized: generated text with exact matches existing within the training data.
- Generalized: generations that do not have exact matches in the data but produce text that follows the same ideas as those in the training data.
- Hallucinated: generations about topics that are neither factually correct nor follow any of the existing conspiracy theories surrounding the topic
Most studies either evaluate memorized vs. generalized text or group memorized and generalized text together to evaluate against hallucinated text. As distinguishing among these three categories without access to training data is exceptionally difficult, we consider both memorized and generalized text as "memorized".
Varying Model Settings
Human Evaluation
Two simple model parameters to evaluate are model size and temperature. To proceed with our analysis, we create a dataset of 17 well-known conspiracy theory topics and generic prompts for each to feed into the model. These are prompts such as "The Earth is" and "The Holocaust is". In order to determine whether a piece of generated text affirms or states a conspiracy theory as fact, we crowdsource with an additional layer of manual inspection. Our findings show that reducing model size drastically lowers the capacity for GPT-2 to retain information about well-known conspiracy theories, as seen in Figure 1.
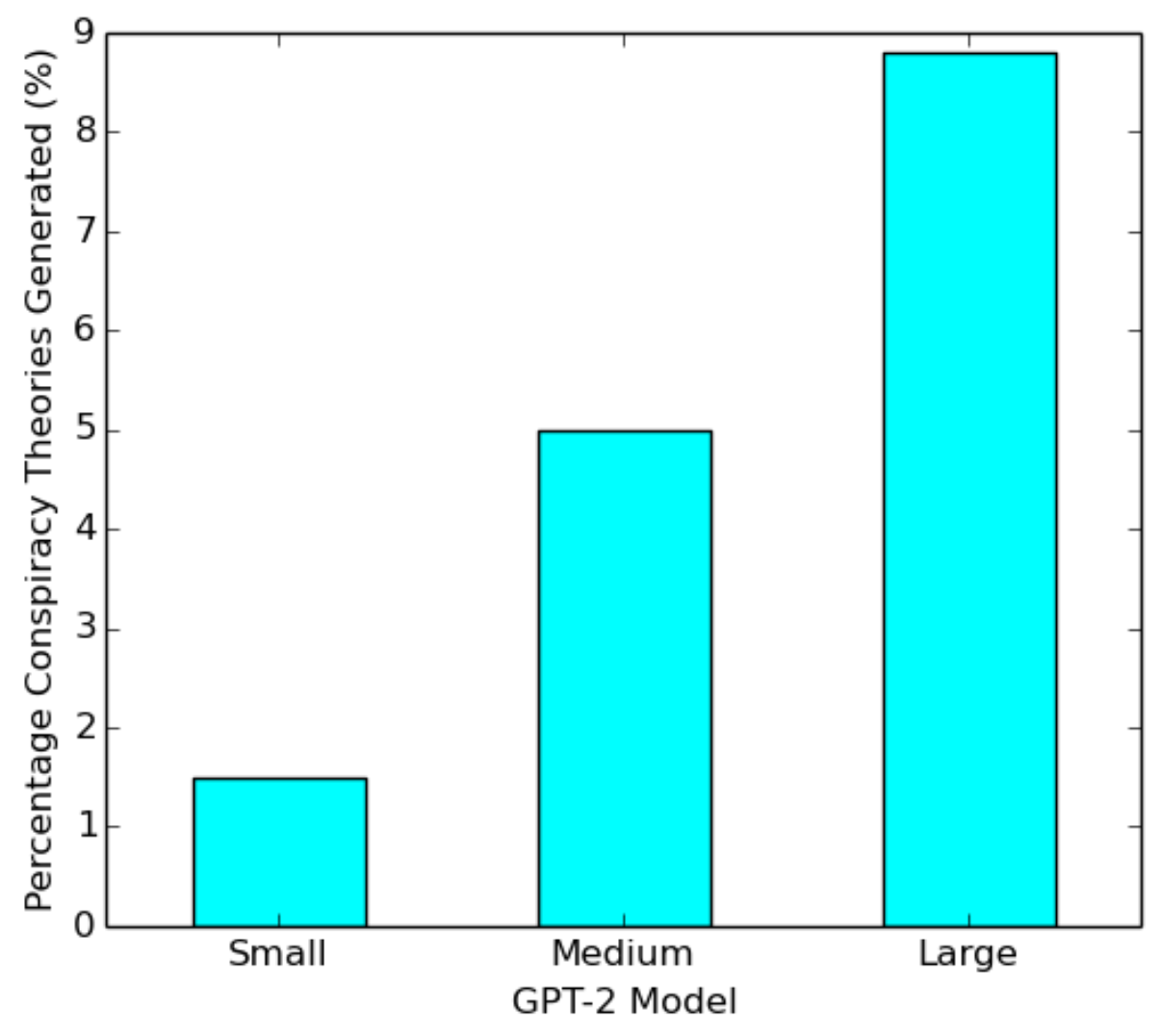
Figure 1—Percentage of conspiracy theories generated by GPT-2 models of size small, medium, and large when prompted on 17 different conspiracy theory topics. Each topic is used to generate 20 sequences for a total of 340 generations.
We further evaluate changes in temperature while controlling for model size. By decreasing the temperature during generation, we are able to reduce randomness in the model's outputs. We can then analyze the curve of produced conspiracy theories and discover the topics for which the model has deeply memorized conspiracy theories (Figure 2).
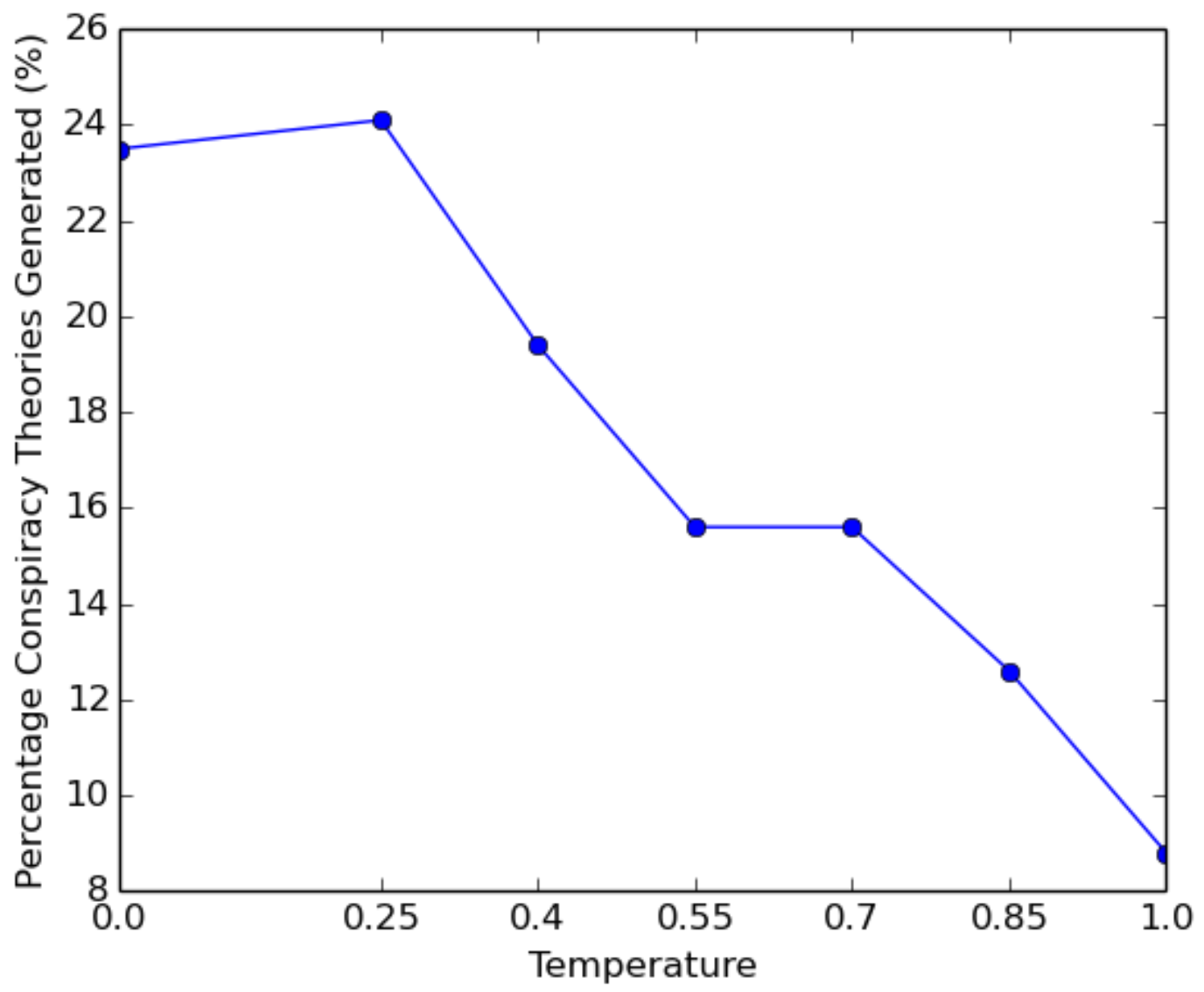
Figure 2—Percentage of conspiracy theories generated by GPT-2 Large at varying temperatures when prompted on 17 different conspiracy theory topics. Each topic is used to generate 20 sequences for a total of 340 generations.
Automated Evaluation
Performing human evaluation while probing for model memorization is not necessarily efficient. Therefore, we take steps to automatically evaluate NLG models for the memorization and generation of conspiracy theories. To do this we:
- Generate several thousand sequences of text with the prompt "The conspiracy theory is that" and extract the generated text without the prompt at different temperature settings.
- Calculate the BLEU score for each generated sequence against the first page of Google search results for the text.
- Calculate the perplexity of each generated sequence for each GPT-2 model size.
- Compute the correlation of the BLEU Google results scores with GPT-2 perplexity.
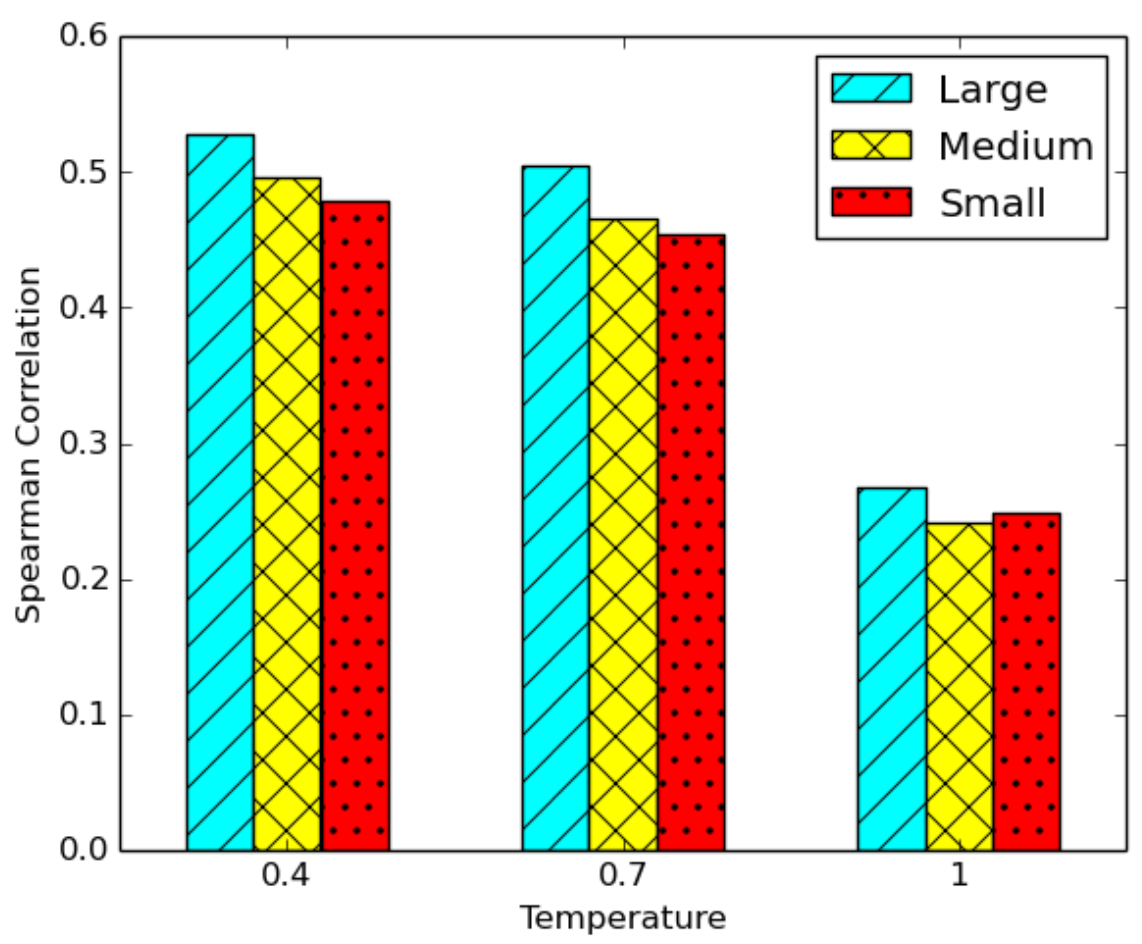
Figure 3—Spearman correlation of model perplexity vs. Google search BLEU score for GPT-2 generated conspiracy theories across varying temperature settings. Each generated theory is evaluated against the first page of Google search results with the BLEU metric.
Our results can be seen in Figure 3. These follow our human evaluation results and show a strong relationship between a generated conspiracy theory’s perplexity and its appearance in Google search results for larger model sizes and lower temperatures. This can allow future research to move towards the creation of automated evaluation metrics for difficult tasks such as text memorization.
Linguistic Analysis
In addition to evaluating how different model settings affect the generation of memorized conspiracy theories, we further investigate whether we find any patterns among different linguistic properties in our generated sequences. Figures 4 and 5 show results for sentiment analysis and linguistic diversity (with BERTScore), respectively.
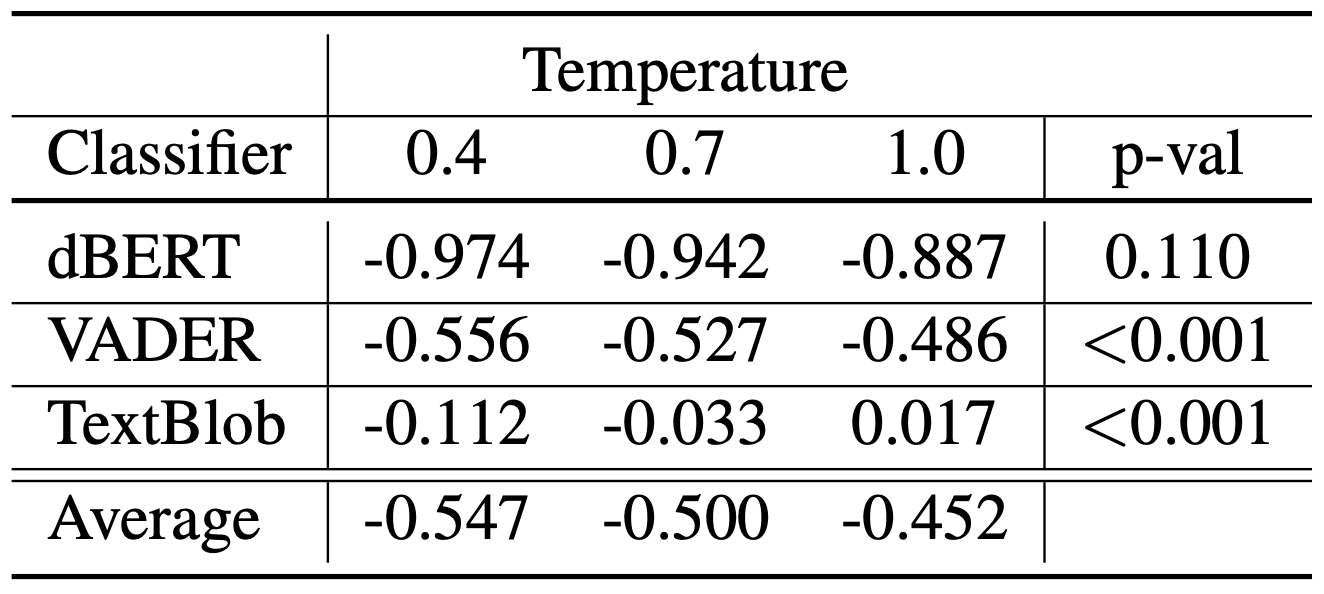
Figure 4—Comparison of average sentiment scores across GPT-2 Large generated conspiracy theories with the DistilBERT (dBERT), VADER, and TextBlob sentiment classifiers along with the Wilcoxon rank-sum p-values for generation pairs of temperature 0.4 and 1. The conspiracy theories are generated at the temperature values of 0.4, 0.7, and 1.0 and sentiment scores range from -1 to 1.
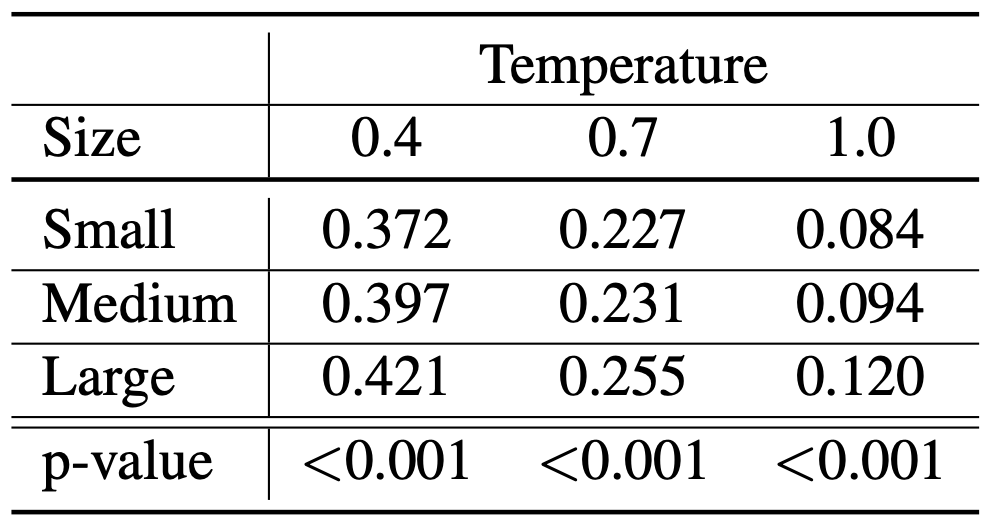
Figure 5—Comparison of average BERTScore values across Wikipedia topic-prompted GPT-2 generations for varying model sizes and temperatures. Generations for each size-temperature pair are evaluated against other generations for their specific topic. Wilcoxon rank-sum p-values for the large-small model pairs at each temperature are listed at the bottom.
When analyzing these two properties against various model settings, we learn:
- All three sentiment analysis models exhibit the same downward trend among score and temperature values. As such, the generated texts at these lower temperature levels are associated with strong negative emotions.
- As the temperature increases and model size decreases, the textual similarity across generations for each topic decreases. This further confirms our human evaluated results of more memorization at larger model sizes, which allows for the generation of contextually aligned outputs for specific topics.
Moving Forward
In our work, we study the generation of harmful text in NLG models. This behavior can be traced to the memorization of training data and as such, we outline a few steps that can be taken to reduce this harm.
- Clean datasets of misinformation and biases before training.
- Supplementing the existing dataset with a smaller "clean" dataset to oversample truthful/non-harmful information.
- Restrict model size.
While each of these has its drawbacks (such as lower generation quality), the general minimization of harmful generation is of great importance and should be accounted for in future models.